








我明白,有时无法获得更多数据。比如,在数据科学竞赛中,训练集的数据量是无法增加的。但对于企业项目,我建议,如果可能的话,去索取更多数据。这会减少由于数据集规模有限带来的痛苦。
2. 处理缺失值和异常值
训练集中缺失值与异常值的意外出现,往往会导致模型正确率低或有偏差。这会导致错误的预测。这是由于我们没能正确分析目标行为以及与其他变量的关系。所以处理好缺失值和异常值很重要。
仔细看下面一幅截图。在存在缺失值的情况下,男性和女性玩板球的概率相同。但如果看第二张表(缺失值根据称呼“Miss”被填补以后),相对于男性,女性玩板球的概率更高。
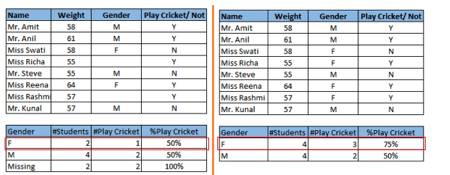
左侧:缺失值处理前;右侧:缺失值处理后
从上面的例子中,我们可以看出缺失值对于模型准确率的不利影响。所幸,我们有各种方法可以应对缺失值和异常值:
-
缺失值:对于连续变量,可以把缺失值替换成平均值、中位数、众数。对于分类变量,可以把变量作为一个特殊类别看待。你也可以建立模型预测缺失值。KNN 为处理缺失值提供了很好的方法。想了解更多这方面内容,推荐阅读《Methods to deal and treat missing values》。
-
异常值:你可以删除这些条目,进行转换,分箱。如同缺失值,你也可以对异常值进行区别对待。想了解更多这方面内容,推荐阅读《How to detect Outliers in your dataset and treat them?》。
3. 特征工程学
这一步骤有助于从现有数据中提取更多信息。新信息作为新特征被提取出来。这些特征可能会更好地解释训练集中的差异变化。因此能改善模型的准确率。
假设生成对特征工程影响很大。好的假设能带来更好的特征集。这也是我一直建议在假设生成上花时间的原因。特征工程能被分为两个步骤:
-
特征转换:许多场景需要进行特征转换:
-
A) 把变量的范围从原始范围变为从 0 到 1 。这通常被称作数据标准化。比如,某个数据集中第一个变量以米计算,第二个变量是厘米,第三个是千米,在这种情况下,在使用任何算法之前,必须把数据标准化为相同范围。
B) 有些算法对于正态分布的数据表现更好。所以我们需要去掉变量的偏向。对数,平方根,倒数等方法可用来修正偏斜。
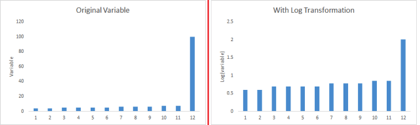
C) 有些时候,数值型的数据在分箱后表现更好,因为这同时也处理了异常值。数值型数据可以通过把数值分组为箱变得离散。这也被称为数据离散化。
-
创建新特征:从现有的变量中衍生出新变量被称为特征创建。这有助于释放出数据集中潜藏的关系。比如,我们想通过某家商店的交易日期预测其交易量。在这个问题上日期可能和交易量关系不大,但如果研究这天是星期几,可能会有更高的相关。在这个例子中,某个日期是星期几的信息是潜在的。我们可以把这个信息提取为新特征,优化模型。
小编推荐
视频推荐
更多 








手游风云榜
更多 












资讯阅读
更多 -

- 《热血江湖手游技能加点攻略》(掌握技能加点要诀,成就无敌江湖之王)
- 业内资讯 2025-05-21
-

- 新版本赏金玩法出装攻略(全面解析最优出装方案,让你在新版本赏金玩法中独领风骚)
- 业内资讯 2025-05-20
-
- 老鼠铲子出装铭文攻略(打造无敌老鼠!)
- 业内资讯 2025-05-20
-

- 王者太虚战场出装攻略(打造最强装备,征服太虚战场)
- 业内资讯 2025-05-19
-
- 制裁战神队友出装攻略(打造最强战队,击败敌人无往不胜)
- 业内资讯 2025-05-19
-
- 《狐狸端游联盟出装攻略》(狐狸出装攻略,助你战胜对手!)
- 业内资讯 2025-05-18
-
- 王者荣耀(揭开哪吒输出利器,带你稳定carry全场)
- 业内资讯 2025-05-18
-
- 地狱男爵技能加点攻略
- 业内资讯 2025-05-16
-
- 逐梦三国(揭秘孙权如何在起凡中成为绝对强者)
- 业内资讯 2025-05-16
-
- 《凯德出装铭文推荐攻略,助你稳定击败对手》
- 业内资讯 2025-05-13
-

- 护卫乌龟出装攻略(如何选择适合乌龟的护卫出装)
- 业内资讯 2025-05-11
-

- 《公主级2-6攻略技能大揭秘》(掌握攻略技能,成为公主级2-6的王者!)
- 业内资讯 2025-05-08