








Hadoop,十岁生日快乐!
于2006年1月28日诞生的它改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,形成了自己的极其火爆的技术生态圈,并受到非常广泛的应用。InfoQ特别策划了系列文章,为大家梳理Hadoop这十年的变化,以及技术圈的生态状况,这是为Hadoop庆生的第一篇。
一张图回顾Hadoop十年
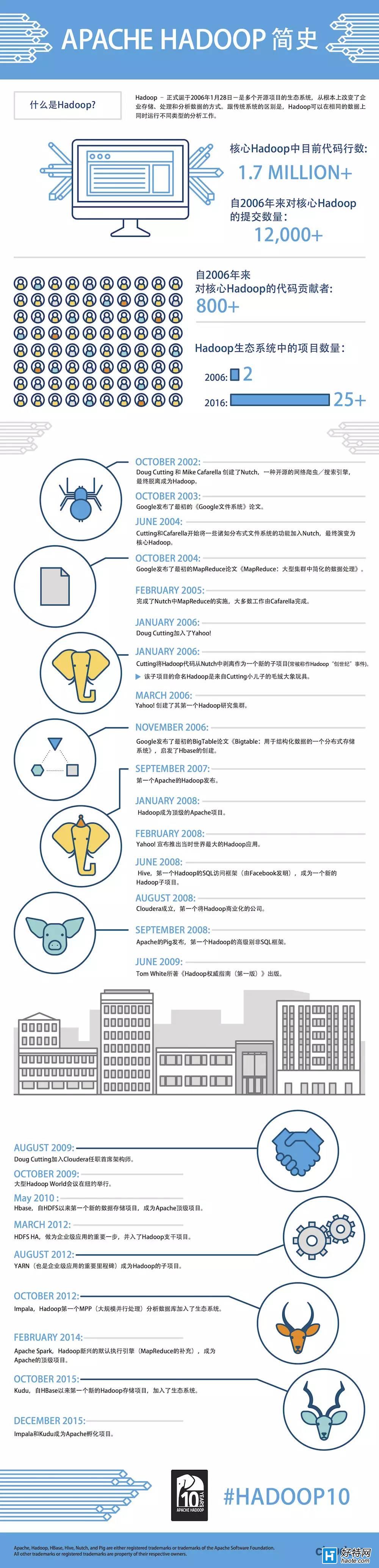
大数据指的是规模超过现有数据库工具获取、存储、管理和分析能力的数据集,并同时强调并不是超过某个特定数量级的数据集才是大数据。
by 麦肯锡《大数据:创新、竞争和生产力的下一个前沿领域》
大数据的定义聚焦在“大“。从表面上看,数据规模的增长的确为处理数据带来了很大的问题。具体来说,在同样时间内获取与以前相同价值的数据变得不可为了。换言之,本质问题是数据的价值密度变低了,数据交换速率变慢了,所以催生了很多新型数据处理技术和工具,如Google的GFS和MapReduce,Apache Hadoop生态系统,美国伯克利大学AMPLab的Spark等;出现了对时间敏感程度不同的计算模式,如批式计算模式、交互式计算模式、流计算模式、实时计算模式等。计算模式的差异只是决定获取价值的技术不同,取决于上层业务需求的不同。
实际上,所谓大数据问题的本质应是数据的资产化和服务化,而挖掘数据的内在价值是研究大数据的最终目标。
2缘起大数据缘起于GoogleGoogle在搜索引擎上所获得的巨大成功,很大程度上是由于采用了先进的大数据管理和处理技术,是针对搜索引擎所面临的日益膨胀的海量数据存储问题以及在此之上的海量数据处理问题而设计的。
Google提出了一整套基于分布式并行集群方式的基础架构技术,利用软件的能力来处理集群中经常发生的节点失效问题。Google使用的大数据平台主要包括五个相互独立又紧密结合在一起的系统:分布式资源管理系统Borg,Google文件系统(GFS),针对Google应用程序的特点提出的MapReduce 编程模式,分布式的锁机制Chubby以及大规模分布式数据库BigTable。
小编推荐
视频推荐
更多 







手游风云榜
更多 












资讯阅读
更多 -

- 《热血江湖手游技能加点攻略》(掌握技能加点要诀,成就无敌江湖之王)
- 业内资讯 2025-05-21
-

- 新版本赏金玩法出装攻略(全面解析最优出装方案,让你在新版本赏金玩法中独领风骚)
- 业内资讯 2025-05-20
-
- 老鼠铲子出装铭文攻略(打造无敌老鼠!)
- 业内资讯 2025-05-20
-

- 王者太虚战场出装攻略(打造最强装备,征服太虚战场)
- 业内资讯 2025-05-19
-
- 制裁战神队友出装攻略(打造最强战队,击败敌人无往不胜)
- 业内资讯 2025-05-19
-
- 《狐狸端游联盟出装攻略》(狐狸出装攻略,助你战胜对手!)
- 业内资讯 2025-05-18
-
- 王者荣耀(揭开哪吒输出利器,带你稳定carry全场)
- 业内资讯 2025-05-18
-
- 地狱男爵技能加点攻略
- 业内资讯 2025-05-16
-
- 逐梦三国(揭秘孙权如何在起凡中成为绝对强者)
- 业内资讯 2025-05-16
-
- 《凯德出装铭文推荐攻略,助你稳定击败对手》
- 业内资讯 2025-05-13
-

- 护卫乌龟出装攻略(如何选择适合乌龟的护卫出装)
- 业内资讯 2025-05-11
-

- 《公主级2-6攻略技能大揭秘》(掌握攻略技能,成为公主级2-6的王者!)
- 业内资讯 2025-05-08