








逻辑回归模型
与主成分分析不同的是,在逻辑回归模型中,训练和打分的操作都是需要计算的,而且都是极其密集的运算。在这种模型的通用的数据训练方案中包含一些对于整个数据集矩阵的转置和逆运算。
由于计算的复杂性,R在训练和打分都需要过好一会儿才能完成,准确的说是7个小时,而Spark只用了大概5分钟。
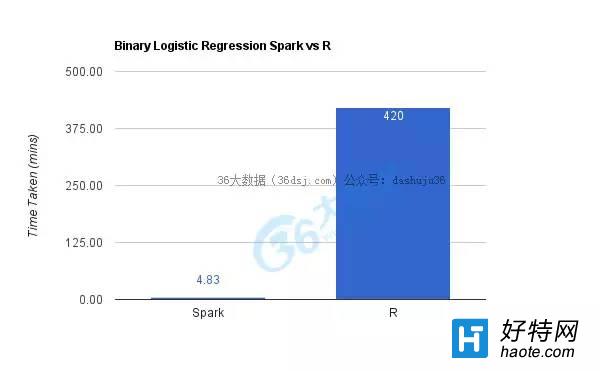
这里我在45个从0到9的双位数字上运行了二元逻辑回归模型,打分/验证也是在这45个测试数据上进行的。
我也并行执行了多元逻辑回归模型,作为多类分类器,大概3分钟就完成了。而这在R上运行不起来,所以我也没办法在数据上进行对比。
对于主成分分析,我采用AUC值 [译者注: AUC的值就是计算出ROC曲线下面的面积,是度量分类模型好坏的一个标准。] 来衡量预测模型在45对数据上的表现,而Spark和R两者运行的模型结果的AUC值差不多。
朴素贝叶斯分类器
与主成分分析和逻辑回归不一样的是,朴素贝叶斯分类器不是密集计算型的。其中需要计算类的先验概率,然后基于可用的附加数据得到后验概率。[译者注:先验概率是指根据以往经验和分析得到的概率,它往往作为”由因求果”问题中的”因”出现的概率;后验概率是指在得到“结果”的信息后重新修正的概率,是“执果寻因”问题中的”果”。]
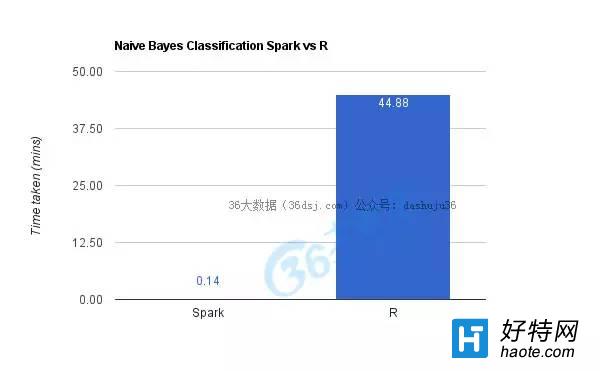
如上图所示,R大概花了45余秒完成,而Spark只用了9秒钟。像之前一样,两者的精确度旗鼓相当。
同时我也试着用Spark机器学习运行了决策树模型,大概花了20秒,而这个在R上完全运行不起来。
Spark机器学习入门指南
对比已经足够,而这也成就了Spark的机器学习。 最好是从编程指南开始学习它。不过,如果你想早点尝试并从实践中学习的话,你可能要痛苦一阵子才能将它运行起来吧。
为搞清楚示例代码并且在数据集上进行试验,你需要先去弄懂Spark的RDD [译者注:RDD,Resilient Distributed Datasets,弹性分布式数据集] 支持的基本框架和运算。然后也要弄明白Spark中不同的机器学习程序,并且在上面进行编程。当你的第一个Spark机器学习的程序跑起来的时候,你可能就会意兴阑珊了。
小编推荐
视频推荐
更多 







手游风云榜
更多 












资讯阅读
更多 -

- 《热血江湖手游技能加点攻略》(掌握技能加点要诀,成就无敌江湖之王)
- 业内资讯 2025-05-21
-

- 新版本赏金玩法出装攻略(全面解析最优出装方案,让你在新版本赏金玩法中独领风骚)
- 业内资讯 2025-05-20
-
- 老鼠铲子出装铭文攻略(打造无敌老鼠!)
- 业内资讯 2025-05-20
-

- 王者太虚战场出装攻略(打造最强装备,征服太虚战场)
- 业内资讯 2025-05-19
-
- 制裁战神队友出装攻略(打造最强战队,击败敌人无往不胜)
- 业内资讯 2025-05-19
-
- 《狐狸端游联盟出装攻略》(狐狸出装攻略,助你战胜对手!)
- 业内资讯 2025-05-18
-
- 王者荣耀(揭开哪吒输出利器,带你稳定carry全场)
- 业内资讯 2025-05-18
-
- 地狱男爵技能加点攻略
- 业内资讯 2025-05-16
-
- 逐梦三国(揭秘孙权如何在起凡中成为绝对强者)
- 业内资讯 2025-05-16
-
- 《凯德出装铭文推荐攻略,助你稳定击败对手》
- 业内资讯 2025-05-13
-

- 护卫乌龟出装攻略(如何选择适合乌龟的护卫出装)
- 业内资讯 2025-05-11
-

- 《公主级2-6攻略技能大揭秘》(掌握攻略技能,成为公主级2-6的王者!)
- 业内资讯 2025-05-08